
计算机组成原理
参考文献
- 《计算机组成原理-微课版》-谭志虎
- 仅作参考和知识梳理,还是要好好看书,书上的内容更详细
- CPU中的cache结构以及cache一致性
课程概貌
- 基本部件的结构和组织方式
- 基本运算的操作原理
- 基本部件和单元的设计思想
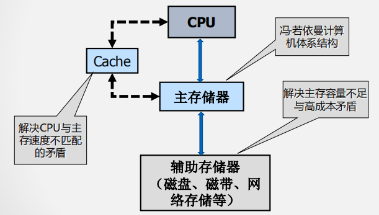
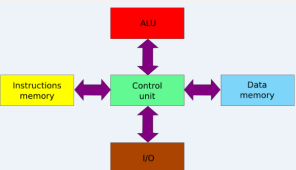
计算机系统概述
冯诺依曼结构计算机工作原理及层次结构分析
冯诺依曼
冯诺依曼计算机的工作原理
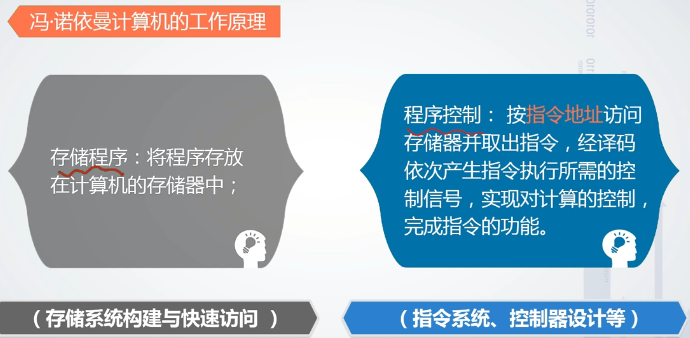
冯诺依曼计算机的组成
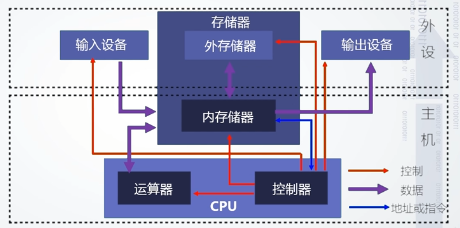
硬件系统
-
运算器
运算器的具体结构与具体的功能相匹配
- 算术运算
- 逻辑运算
- 基本结构 : ALU、寄存器、通路
-
控制器
- 基本功能:产生指令执行过程所需要的所有控制信号,控制相关功能部件执行相应操作。
- 控制信号的形式:电平信号、脉冲信号
- 产生控制信号的依据:指令、状态、时序
- 控制信号的产生方式:微程序、硬布线
信号的产生来源于指令
-
存储器
-
功能:存储原程序、原数据、运算中间结果
-
工作模式:读、写
-
工作原理:按地址访问,读写数据
-
容量与地址线数量的关系
1K = 10,1M = 20,1G = 30
以其位宽为单位,也就是说每个存储器地址下的数据位数为位宽。如
8K*12bit的存储器中的12就是存储器的位宽,指每个存储器地址下数据的位数。
这个12与地址线的多少无关,8K就是指有8K个不同的地址8K=81024=2^? 2的多少次方等于81024就有多少根地址线,8=2^3, 1024=2^10, 那么8K=2^13 ,存储器地址线就为13根。
-
-
输入输出设备
- 输入信息、输出信息
软件系统
核心是算法
- 系统软件:操作系统、网络系统和编译系统
- 支持软件:开发工具、界面工具
- 应用软件:字处理软件、游戏软件
硬件与软件系统间的关系
- 两者相互依存
- 逻辑等效性,硬件软件都可实现某功能
- 协同发展
计算机的层次结构

-
不同层次的差异
-
不同用户处在不同层次
-
不同层次具有不同属性
-
使用工具不同
-
代码效率不同
-
-
理解概念
- 透明性
- 系统观
- 硬件结构发生变换,影响软件
- 不同类型的软件对硬件有不同的要求
- 编程的CPU硬件相关性,编程应查阅对应CPU的编程手册
- 软硬件分界线
- 指令集架构层
- 指令格式、指令设计
计算机系统性能评价
非时间指标
机器字长
指机器一次能处理的二进制位数
- 由加法器、寄存器的位数决定
- 一般与内部寄存器的位数相等(字长)
- 字长越长,表示数据的范围就越大,精度越高
- 目前常见的有32位和64位字长
这个字长从编程语言的角度理解就没意义了。字长要从汇编语言的角度理解,就是指令集里面的运算和内存操作时操作数的长度。比如你写一条load a, reg1,那么a这个操作数的长度就是字长。32位机的字长最大是32bit,64位机的字长最大是64bit。
总线宽度
数据总线一次能并行传送的最大信息位数
- 一般指运算器与存储器之间的数据总线位数
- 内部胃不数据总线宽度可能不一致,根据具体的设计不同。
主存容量
是指一台计算机主存所包含的存储单元总数
存储带宽
指单位时间内与主存交换的二进制信息量,常用单位B/s
存储带宽影响因素:
- 数据位宽
- 数据传输速率
时间指标
主频f/时钟周期T,外频、倍频
-
主频f :CPU内核工作的时钟频率,即CPU内数字脉冲信号振荡的频率,与CPU实际的运算能力之间不是唯一的、直接关系;
-
时钟周期T:节拍周期,是计算机中最基本、最小的时间单位。在一个时钟周期内,CPU仅完成一个最基本的动作。
f与T的关系
互为倒数,f越高,T就越小(f =100MHz时 T=10ns,f =1GHz时T=1ns)。
-
外频:指CPU(内存)与主板之间同步的时钟频率(系统总线的工作频率);
-
倍频:CPU主频与外频之间的倍数;
主频=外频×倍频 如:Pentium 4 2.4G CPU主频2400M = 133M (外频)×18 (倍频)
CPI (Clock cycles Per Instruction)
-
CPI指执行一条指令(平均)需要的时钟周期数**(即T周期的个数)**
-
单条指令CPI、一段程序中所有指令的CPI、指令系统CPI等
程序中所有指令的时钟周期之和m
程序指令总数IC
程序中各类指令的CPI
程序中该类指令的比例P
CPU时间
-
CPU真正花费在该程序上的时间,包括用户CPU时间和系统CPU时间,通常是基于用户CPU时间进行评价。
m为程序中所有指令的时钟周期之和
如考虑CPI:
-
执行一段程序的所需时间
CPU时间+I/O时间+存储访问时间+各类排队时延等
IPC (Instruction per Clock)
-
IPC是每个时钟周期内CPU执行的指令条数 (并行)
-
CPI的倒数
-
CPU性能判断标准应该是:
CPU性能=IPC(CPU每一时钟周期内所执行的指令多少)×频率(MHz时钟速度)
MIPS (Million Instructions Per Second)
-
MIPS每秒钟CPU能执行的指令总条数 (单位:百万条/秒)
全性能公式简写为: $$\begin{aligned}MIPS &= \frac{f}{CPI}=IPC\times f\end{aligned}$$
-
f 单位为Mhz,CPI为T的个数,1Ghz = 1000Mhz
-
考虑MIPS后的CPU时间
时间指标的应用思考
晶振自身产生时钟信号,为各种微处理芯片作时钟参考,晶振相当于这些微处理芯片的心脏,没有晶振,这些微处理芯片将无法工作。
-
f、 CPI、MIPS、CPU时间在评价计算机性能方面的特点和不足?
受编程语言、适配优化等影响
-
计算机性能指标是确定的吗?
硬件或软件指标 影响什么 如何影响 算法 CPI、MIPS、CPU时间 影响指令数量和指令类型 编程语言 CPI、MIPS、CPU时间 指令数量和指令类型 编程程序 CPI、MIPS、CPU时间 影响指令数量和指令类型 指令集体系结构 f/T 、CPI、MIPS、CPU时间 全面影响
计算机性能测试
-
CPU测试工具
-
CPUmark : 综合CPU测试,包括系统存储,浮点运算和逻辑运算;
-
SysID : 测试CPU电压,运行频率,L1 、L2 Cache以及各项技术资料;
-
Hot CPU Tester :可测试机器稳定性,尤其是超频后的稳定性,找出CPU 的最高超频点或缺陷,还可检测CPU的详细性能指标并给出量化的分数值。包括「复杂矩阵」「排序算法」「快速傅立叶变换」「CPU 缓 存」「内存」「硬盘」及指令集等。另外其CPU/Mem Burn-in)还可以作为新购机时的烤机软件来使用。
-
-
显卡测试工具
-
3DMark :除衡量显卡性能外,已渐渐转变成一款衡量整机性能的软件;
已发行3Dmark99、3Dmark 11和The new 3DMark等近10个版本;
-
N-Bench2: 重点测试CPU以及系统图形性能;
-
**FurMark:**通过皮毛渲染算法来衡量显卡的性能及其稳定性,提供了全屏/窗口、预定分辨率、基于时间或帧的测试、多种多重采样反锯齿、竞赛等多种模式。
-
-
硬盘测试工具
- Hard Disk Speed : 硬盘测速软件;
- Disk Benchmark : 通过对不同大小的数据块对磁盘读/写速度的影响,检测硬盘、U盘、 存储卡及其它可移动磁盘的读/写入速率 ;
- iometer : 可被配置为基准测试程序的磁盘和网络I/O的负载,可测试磁盘和网络控制器的性能、总线带宽和时延等参数;
- HDD Temperature Pro: 硬盘温度探测软件。
-
内存测试工具
- CTSPD :选择主板厂商及型号后可详细测试内存的信息,包括:CASlatency (列地址选通时延)、RAS to CAS delay(RAS到CAS的相对延迟时间)、RAS precharge Trp (RAS预充电时间)、DIMM内存生产厂商和DIMM编号等信息。
- Memory Speed: 通过读写不同大小的块状数据来测试内存的性能;
- Memory Transfer Timing Utility :通过对源文件和目标文件进行校正和非校正复制,测试内存的读、写速率;
数据表示
机器数及特点
为什么研究机器内的数据表示
- **目的:**组织数据,方便计算机硬件直接使用
- 要考虑的因素: 数据类型、数据范围、数据精度、存储和处理的代价、软件的可移植性
机器内的数据表示
-
**真值:**符号用“+”、“-”表示的数据表示方法。
-
**机器码\数:**符号数值化的数据表示方法, 用0、1表示符号。
-
三种常见的机器码的公式:设定点数的形式为X0 X1 X2 X3 … Xn。

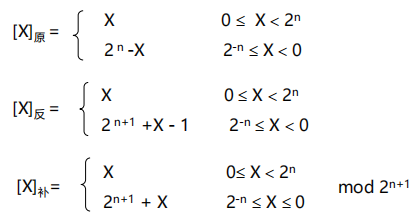
常见机器码的特点
- 原码
- 表示简单: [X]原 = 2 n -X
- 运算复杂:符号位不参加运算,要设置加法、减法器。
- 0的表示不唯一
- [X]原 + [Y]原,不能直接判定是执行加法还是减法运算,分同号和异号
- 反码
- 表示相对原码复杂: [X]反 = 2 n+1 +X - 1
- 运算相对原码简单:符号位参加运算, 只需要设置加法器,但符号位的进位需要加到最低位。
- 0的表示不唯一
- 补码
- 表示相对原码复杂: [X]补 = 2 n+1 +X
- 运算简单:只需设置加法器。
- 0的表示唯一
- 补码中模的概念 (符号位进位后所在位的权值)
阶码:在机器中表示一个浮点数时需要给出指数,这个指数用整数形式表示,这个整数叫做阶码。
当阶码为固定值时,数的这种表示法称为定点表示,这样的数称为“定点数”;当阶码为可变时,数的这种表示法称为浮点表示,这样的数称为“浮点数”。
“移码”用来表示浮点型小数的阶码。对于正数,符号位为“1”,其余位不变,如+1110001的阶码为11110001;对于负数,符号位为“0”,其余位取反,最后加“1”,如–1110001的阶码为00001111。
移码(增码)
-
移码表示浮点数的阶码,IEEE754(二进制浮点数算术标准)中阶码用移码表示。
-
设定点整数X的移码形式为X0X1X2X3…Xn,则移码的定义是:
(X为真值,n为X的整数位位数)
-
具体实现:数值位与X的补码相同,符号位与补码相反。
- 移码的特点:
- 移码的符号位中0表示负数,1表示正数;
- 同一数值的移码和补码除符号位相反外,其他各位相同
- 移码中0的表示也唯一,具体表示为10000…0
总结结论
P24
- 原码、反码、补码是负逻辑,移码是正逻辑。
定点与浮点数据表示
定点数据表示
定点数表示法约定计算机中所有数据的小数点位置固定,其中,
- 将小数点的位置固定在数据的最高位数之前或符号位之后的数据表示为定点小数
- 而将小数点固定在最低位数之后的数据表示称为定点整数。
- 由于小数点位置固定,因此小数点不必再用符号表示,其位置也无须存储。
-
可表示定点小数和整数
-
表现形式(看小数点的位置):
- 小数表示:$X_0 . X_1X_2X_3X_4…X_n $
- 整数表示: $$X_0X_1X_2X_3X_4…X_{n-1}X_n.$$
-
定点小数表示数的范围(补码为例):$ -1 ≤ x ≤ 1-2^{-n} $
-
定点整数表示数的范围(补码为例):
-
定点数据表示数的不足:数据表示范围受限
- 定点数能表示的数据范围影响因素:机器字长、所采用机器数的表示方法。
超出表示范围叫溢出(上、下)、小数叫精度溢出
浮点数据表示
把数的范围和精度分别表示的一种数据表示的方法。
浮点数的使用场合:当数的表示范围超出了定点数能表示的范围时
-
一般格式
E:阶码位数,决定数据的范围
M:尾数位数,决定数的精度
不足:不同系统可能根据自己的浮点数格式从中提取不同位数的阶码
-
浮点数的范围
-
浮点数的规格化
- 使得尾数真值最高有效位为1,既尾数的绝对值应大于或等于$$(0.1)2$$或$$(0.5){10}$$。
-
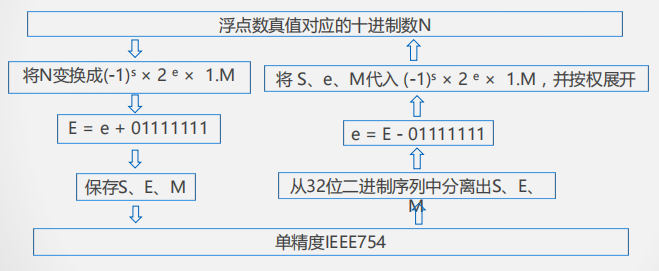
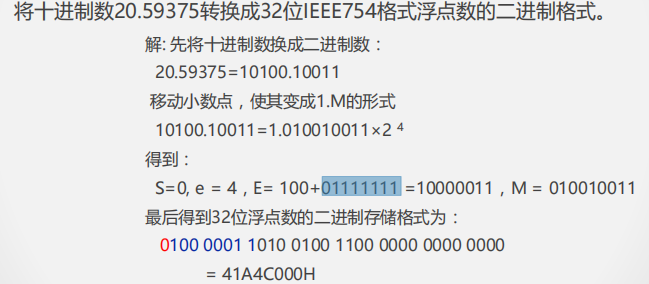
IEEE 754格式
S表示符号位,E是阶码,M表示尾数
对应C语言中的float、double
-
指数采用偏移值,其中单精度偏移值为127,双精度为1023,将浮点数的阶码值变成非负整数,便于浮点数的比较和排序。
Tips:偏移量采用127使得任何一个规格化数的倒数能用另外一个浮点数表示,采用128就会溢出。
-
IEEE754尾数形式为1.XXXXXX,其中M部分保存的是XXXXXX(1被隐藏),从而可保留更多的有效位,提高数据表示的精确度。
-
E=0 , M =0 $$ :表示机器零;
-
1 \le E \le 254 :N = (-1)^S \times 2^{E-127}\times 1.M $$,**规格化的浮点数**
-
E=255 , M \ne 0 :N= NaN$$,表示一个非数值,对应于0 / 0
-
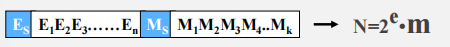


数据校验的基本原理
数据校验的必要性
- 受元器件的质量、电路故障或噪音干扰等因素的影响,数据在被处理、传输、存储的过程中可能出现错误。
- 若能设计硬件层面的错误检测机制,可以减少基于软件检错的代价(系统观)。
校验的基本原理
- 增加冗余码(校验位)
实验1 汉字国标码专区位码实验
汉字表示方法
-
机内码
-
区位码:4位10进制
- 94*94矩阵 ,编号从一开始
- GB2312汉字机内码 = 区位码 + 0xA0A0
-
字形码:输出汉字点阵的信息编码
- 点阵信息量大,所占存储空间大
- 用来构建汉字字库,不能用于机内存储

实验
关系式
国标码=区位码(十六进制)+2020H
区位码=国标码+FFFF-2020H+0001H=国标码+dfe0
由于采用加法器,所以用补码的形式表示,-2020H的补码为def0
运算方法与运算器
定点数运算及溢出检测
定点数加法运算
b表示补
\begin{align}[X]_b+[Y]_b=[X+Y]_b\quad mod 2^{n+1}\end{align}
定点数减法运算
\begin{align}[X-Y]_b=[X]_b− [Y]_b =[X]_b+[− Y]_b\end{align}
-
[Y]补 =10011 求 [–Y]补 =01101
-
通过右向左扫描[Y]补 ,在遇到数字1及之前,直接输出遇到的数字,遇到1之后,取反输出,即可得到[-Y]补,反之亦然!
-
X=+10101 Y=+ 10010 求X-Y
[X]补=010101 , [Y]补=010010 , [-Y]补=101110
[X-Y]补=[X]补+[-Y]补=010101+101110
=1 000011
所以: X - Y=+ 000011
数溢出的概念及其判断方法
-
溢出的概念
运算结果超出了某种数据类型的表示范围。
1.已知 X=+ 10010 Y= +10101 求X+Y
[X]补=010010 [Y]补= 010101
[X+Y]补=[X]补+[Y]补=010010 + 010101
=100111
所以: X+Y= - 11001
2.已知 X=- 10010 Y= -10101 求X+Y
[X]补=101110 [Y]补= 101011
[X+Y]补=[X]补+[Y]补= 101110 + 101011
=1 010001
所以: X+Y= + 010001
-
溢出的检测方法
溢出只可能发生在同符号数相加时,包括[X]补与[Y]补; [X]补 与[-Y]同号
-
方法:对操作数和运算结果的符号位进行检测,当不相同时就表明发生了溢出。(设X0 ,Y0 为参加运算数的符号位, S0 为结果的符号位),则有:
\begin{align} V = X_0Y_0\overline{S_0} + \overline{X_0}\ \overline{Y_0} S_0 \end{align}
两个数据符号位为负,结果符号位为正即为溢出,相反也适用。
-
方法:对最高数据位进位和符号进位进行检测。设运算时最高数据位产生的进位为C1,符号位产生的进位为C0,溢出检测电路为:
\begin{align} V = C_0 \oplus C_1 \end{align}
-
用变形补码
溢出的判断:
已知 X=- 10010 Y= -10101 求X+Y
解: [X]补 = 1101110 [Y]补 = 1101011
[X+Y]补=[X]补+[Y]补= 1101110 + 1101011
=1 10 10001
V= 1 异或 0 =1 故发生溢出!
-
-
溢出判断的软件方法
int tadd_ok(int x,int y) {
int sum=x+y;
int neg_over = x<0 && y<0 && sum>=0;
int pos_over= x>=0 && y>=0 && sum<0;
return !neg_over && !pos_over;
} -
体会软/硬件功能的等效性和差异性!体会软/硬协同的系统观!

无符号数运算的溢出判断
-
无符号数加法的溢出可用ALU的进位表示
-
无符号数减法的溢出也可用带加/减功能的ALU的进位取反后表示。
定点数补码加、减运算器设计
可控加减法
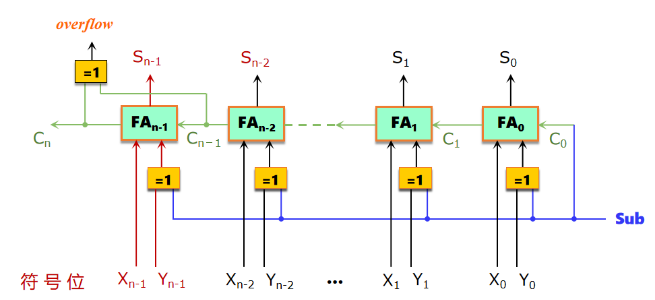
并行加法器

①生成P*,G*需5T ②生成C3/C12需2T ③计算进位需2T ④求和3T
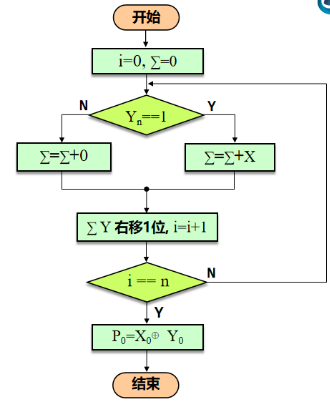
原码一位乘法
存储系统
存储系统层次结构
基本存储体系

主存速度慢的原因
- 主存增速与CPU增速不同步
- 指令执行期间多次访问存储器
主存容量不足的原因
- 存在制约主存容量的技术因素由CPU、主板等相关技术指标确定
- 指令集、单双通道等
- 应用对主存的需求不断扩大
- 价格原因
存储体系的层次化结构
-
CPU访问到的存储系统具有Cache的速度,辅存的容量和价格
-
L1 Cache集成在CPU中,分数据Cache(D-Cache)和指令Cache(I-Cache)
-
早期L2 Cache在主板上或与CPU集成在同一电路板上。随着工艺的提高L2 Cache被集成在CPU内核中,不分D-Cache和I-Cache
-
哈佛结构
-
是一种将指令储存和数据储存分开的存储器结构,可支持:数据和指令并行储存、指令预取,提高处理器的执行效率;另外,指令和数据可有不同的数据宽度,如Microchip 公司的PIC16芯片的程序指令是14位宽度,而数据是8位宽度。
-
目前使用哈佛结构的:PIC系列、摩托罗拉公司的MC68系列、Zilog公司的Z8系列、
ATMEL公司的AVR系列和ARM公司的ARM9、ARM10和ARM11。
-
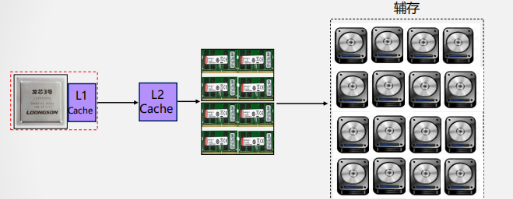
存储体系层次化结构的理论基础

-
局部性原理
-
时间局部性
- 现在被访问的信息2在不久的将来还将再次被访问;
- 时间局部性的程序结构体现: 循环结构
-
空间局部性
- 现访问信息2 ,下一次访问2附近的信息。
- 空间局部性的程序结构体现:顺序结构
-
主存中的数据组织
存储字长
- 主存的一个存储单元所包含的二进制位数;
- 目前大多数计算机的主存按字节编址,存储字长也不断加大,如16位字长、32位字长和64位字长;
- ISA(指令集架构)设计时要考虑的两个问题
- a)如何根据字节地址读取一个32位的字?
- 字的存放问题
- b)一个字能否存放在主存的任何字节边界?
- 字的边界对齐问题
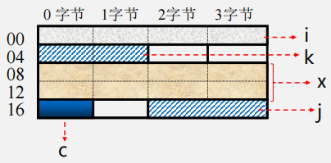
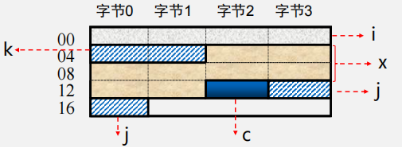
数据存储与边界的关系
-
按边界对齐的数据存储
-
int i, short k, double x, char c, short j,…… (32位系统中)
-
-
未按边界对齐的数据存储
- 虽节省了空间,但增加了访存次数,需要在性能与容量间权衡。
-
边界对齐与存储地址的关系(以32位为例)
- 双字长数据边界对齐的起始地址的最末三位为000(8字节整数倍;
- 单字长边界对齐的起始地址的末二位为00(4字节整数倍);
- 半字长边界对齐的起始地址的最末一位为0(2字节整数倍)。
-
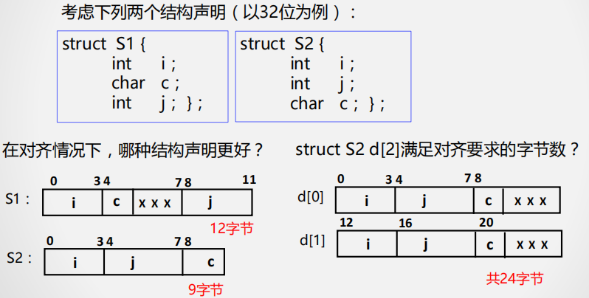
例题
大端小端方式
-
Big-endian: 最高字节地址(MSB)是数据地址
-
Little-endian: 最低字节地址(LSB)是数据地址
-
有的机器两者都支持,但需要设定.
-
例如设某程序执行前 r0 =0x 11223344执行下列指令:
-
r1=0x100
-
STR r0, [r1]
-
LDRB r2 ,[r1]
小端模式下: r2=0x44
大端模式下: r2=0x11
-
-
无论是大端还是小端,每个系统内部是一致的,但在系统间通信时可能会发生问题!因为顺序不同,需要进行顺序转换;


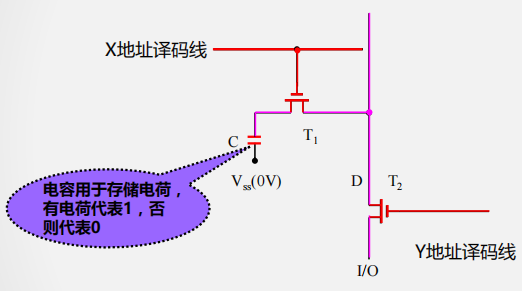
静态存储器工作原理
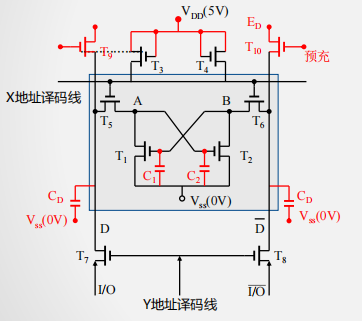
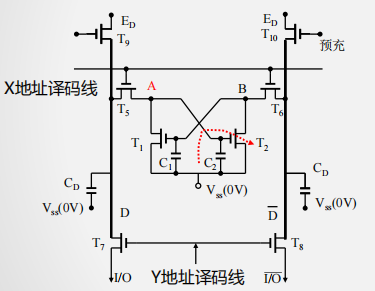
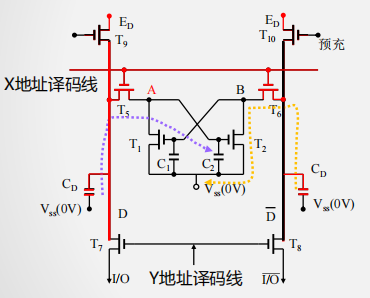
SRAM存储单元结构
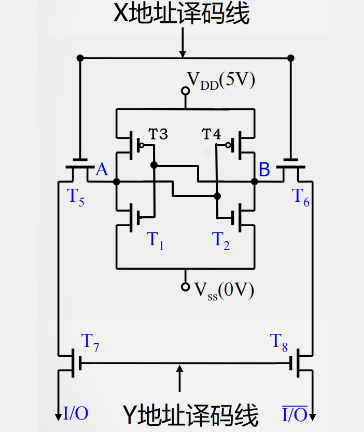
- 工作管: T1、 T2 (保存数据)
- 负载管: T3、 T4 (补充电荷)
- 门控管: T5、T6 、T7、T8 (开关作用)
SRAM存储单元工作原理
- X地址选通(行选通)
- T5、T6管导通
- A点与位线相连
- Y地址选通(列选通)
- T7、T8管导通
- A点电位输出到I/O端
- 写过程
- X有效→ T5、 T6 通 → A与 I/O 连通
- Y有效→ T7、 T8 通 → B与 I/O 连通
- 写1
- I/O=1 →A= 1→ T2 通→ B=0 → T1 截止
- I/O=0 →B= 0→ T1截止→ A=1 → T2通
- 此时, T1、T2形成了稳态: A=1、B=0
- 写0
- I/O=0 →A= 0→ T2截止 → B=1 → T1通
- I/O=1 →B= 1→ T1 通→A=0 → T2 截止
- 此时, T1、T2形成了稳态,B=1、A=0
- 读过程
- X有效→ T5、 T6 通 → A与 I/O 连通
- Y有效→ T7、 T8 通 → B与 I/O 连通
- 通过外接于I/O与 I/O间的电流放大器中的电流方向可判断读出的是1还是0(与写入时定义的1和0有关)
- 无论读/写,都要求X和 Y 译码线同时有效
- 保持
- X、 Y撤销后,由负载管 T3、 T4 分别为工作管T1、 T2 提供工作电流,保持其稳定互锁状态不变。
静态存储器的结构
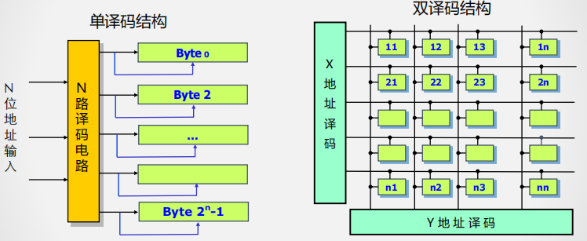
- 单译码结构:N位地址,寻址个存储单元,根译码线
- 双译码结构:N位地址,寻址个存储单元,根译码线
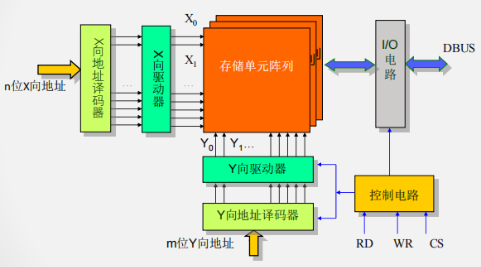
-
例子
- 行、列地址各有多少位?


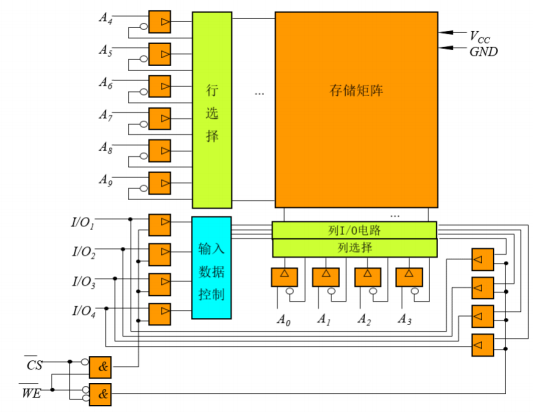
动态存储器工作原理
SRAM存储单元的不足
- 晶体管过多
- 存储密度低
- 功耗大
DRAM存储单元的基本结构
-
解决SRAM不足采取的方法:
-
提升存储密度
-
降低功耗
-
降低成本
-
利用栅极分布电容缓存电荷
-
增加电路协同存储单元工作
-
DRAM存储单元的工作原理
-
写操作
-
Y地址选通
-
T7、T8管导通
-
I/O端数据写入到位线
-
-
X地址选通
- T5、T6管导通
- 位线与C2、C1相连
-
-
读操作
-
给出预充信号
- T9、T10导通
- 充电电压给CD充电(充满)
-
撤除预充信号
-
X地址选通
- T5、T6管导通
- 右CD通过C1放电
- 左CD给C2充电
-
Y地址选通
- T7、T8管导通
- 左CD 与右CD间形成放电电流
-
读过程比写复杂、速度慢
-
-
保持操作
- X地址选通信号撤销
- Y地址选通信号撤销
- 栅极电容容量有限,可持续的时间很短
-
刷新操作(相当于写)
-
给出预充信号
- T9、T10导通
- 充电电压给左右CD充电
-
撤除预充信号
-
X地址选通
- T5、T6管导通
- 右CD通过C1放电
- 左CD给C2充电
-
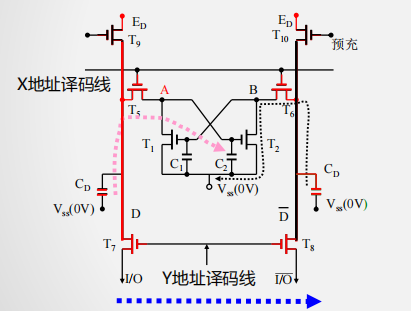
DRAM存储单元的刷新
- 刷新周期:两次刷新之间的时间间隔;
- 双译码结构的DRAM刷新按行进行,需要知道RDAM芯片存储矩阵的行数;
- 刷新地址由刷新地址计数器给出。
- 1s /1000= 1ms =1000µs=1000000ns
集中刷新
-
假定刷新周期为2ms, DRAM 内部128行,读写周期0.5µs
-
采用集中刷新的存储器平均读写周期
\begin{align}\overline{T} = \frac{2\mu s}{(4000-128)}=0.5165\mu s\end{align}
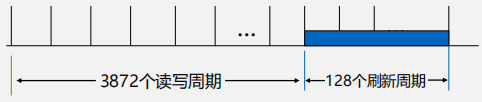
分散刷
-
假定刷新周期为2ms, DRAM 内部128行,读写周期0.5µs

异步刷新
-
假定刷新周期为2ms, DRAM 内部128行,读写周期0.5µs

\begin{align}\overline{T} = \frac{2ms}{(4000-128)}=0.5165\mu s\end{align}
DRAM与SRAM的对比
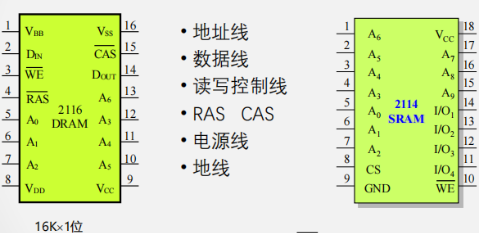
- DRAM: 地址线复用,RAS非兼为片选信号
其它结构的DRAM存储单元
- 进一步提高存储密度
- 裁剪冗余电路
- 核心是电容
存储扩展
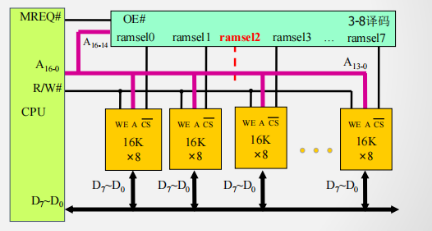
存储扩展的基本概念及类型
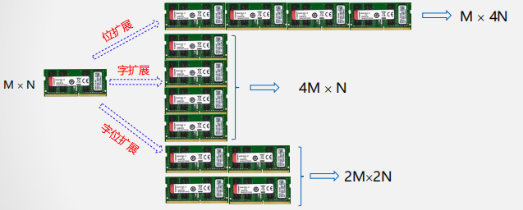
位扩展举例
-
用16K x 8 的存储芯片构建16K x 32的存储器
-
所需芯片数量:
-
所有存储芯片并行工作,贡献32位数据中的不同8位
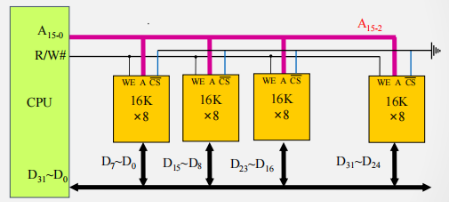
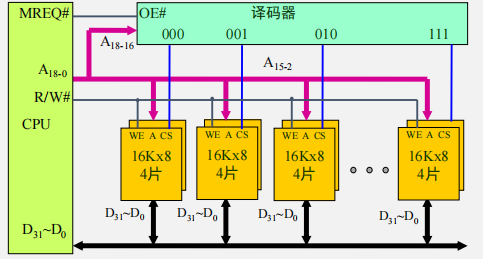
字扩展举例
-
例2 用16K x 8 的存储芯片构建128k x 8的存储器
- 所需芯片数量:128K * 8/ (16K * 8) = 8
-
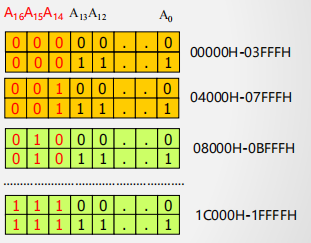
计算每片的全局地址空间
-
计算对应于存储空间08000H ~ 0BFFFH的容量:
-
例3 用16K x 8 的存储芯片构建128K x 8的存储器,其中08000H ~ 0BFFFH存储空间保留不用 .
-
所需芯片数量:(128K - **16k *) 8/ (16K*8) = 7
-
保留不用则减去即可,每片都要减
-
-
例4 用16K x 8 的存储芯片构建128K x 32的存储器



多体交叉存储器
提出背景
- 其基本思想是在不提高存储器速率、不扩展数据通路位数的前提下,通 过存储芯片的交叉组织,提高CPU单位时间内访问的数据量,从而缓解 快速的CPU与慢速的主存之间的速度差异。
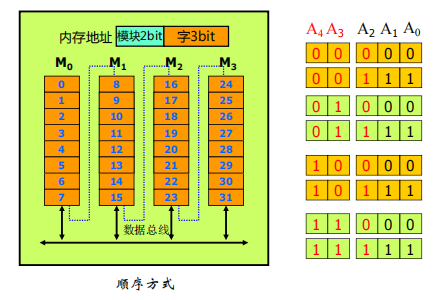
高位多体交叉存储器
-
特点
- 数据组织特点:相邻地址 的数据处于同一存储体
- 一个地址寄存器
- 多模块串行(局部性原理)
- 性能无提升
- 扩充容量方便
-
缺点
- 往往导致一个存储体访问频繁,其他存储体处于空闲状态,不能并行工作
低位多体交叉存储器
- 特点
- 每个存储体均需地址寄存器
- 多模块并行(局部性原理)
- 性能提升
- 扩充容量也方便

-
通过4个存储体的并行工作,可实现对存储器的流水线方式访问
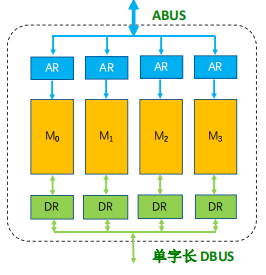
低位多体交叉存储器的性能分析
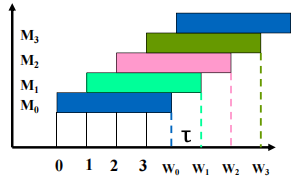
- 上图为 m=4 时,CPU以 流水方式访问各存储模块的示意图
- 设存储周期为 T ,总线传送周期为$ τ$,交叉模数为m。
- 流水线方式存取的条件:
-
即每个模块启动后经过$ τ$ 时间的延时,就可以启动下一个模块。
-
连续并行读m 个字的时间:
-
顺序读m 个字的时间:
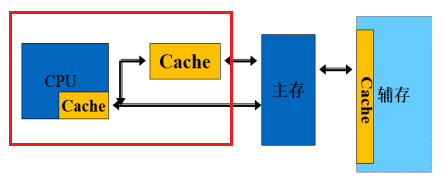
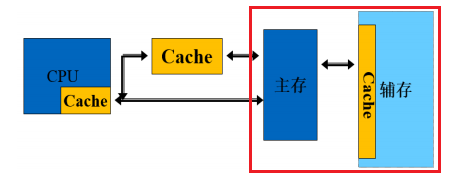
Cache的基本原理
CPU中的Cache
举个例子,当你在思考一个问题的时候,寄存器存放的是你当前正在思考的内容,cache存放的是与该问题相关的记忆,主存则存放无论与该问题是否有关的所有记忆,所以,寄存器存放的是当前CPU执行的数据,而cache则缓存与该数据相关的部分数据,因此只要保证了cache的一致性,那么寄存器拿到的数据也必然具备一致性。
-
单核CPU
- 在单核CPU结构中,为了缓解CPU指令流水中cycle冲突,L1分成了指令(L1P)和数据(L1D)两部分,而L2则是指令和数据共存。
-
双核CPU
-
多核CPU的结构与单核相似,但是多了所有CPU共享的L3三级缓存。在多核CPU的结构中,L1和L2是CPU私有的,L3则是所有CPU核心共享的。
-

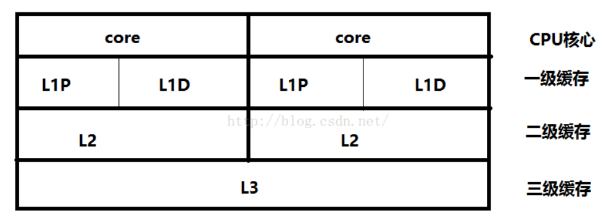
存储系统中的Cache 视图
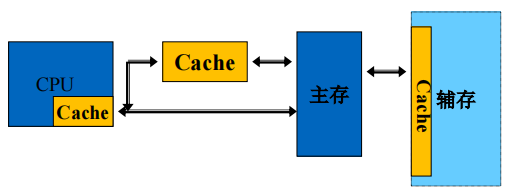
- Cache的功能:
- 缓解快速CPU与慢速的主存之间的速度差异
- Cache的理论基础:
- 局部性原理
Cache 的工作过程
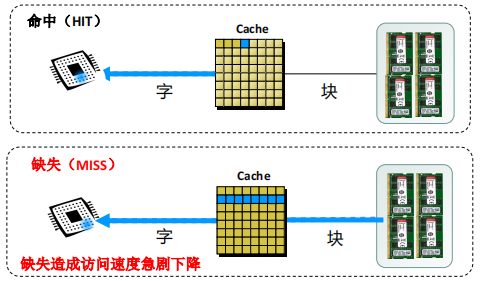
读流程
-
命中与缺失
- CPU需要访问主存时,首先以主存地址RA中的主存块地址为关键字在查找表中进行数据查找,如果能查找到对应数据,表示命中,否则表示数据缺失。
- 数据命中,则根据查找表提供的信息访问对应的cahe数据块,再将读出的数据信息送入CPU,数据命中时访问时间最短。
- 数据缺失,则访问慢速的主存,为了利用空间局部性,需要将RA地址所在的主存数据块副本载入cache。载入时可能存在cache已满或载入位置有数据冲突的情况,此时需要利用替换算法腾空位置,载入后还需要更新查找表,方便后续查找。
有关替换算法,访问https://blog.csdn.net/badmer/article/details/118305208
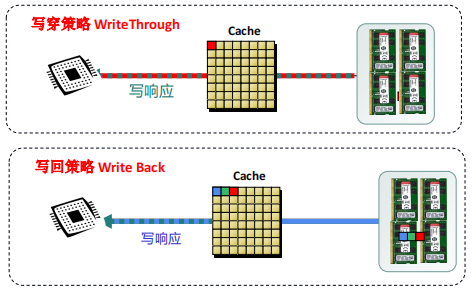
写流程
-
写穿策略和写回策略
-
首先以主存字节地址WA中的主存块地址为关键字在查找表中进行数据查找,如果能查找到对应的数据,表示数据命中,否则表示数据缺失。
-
数据命中时,可以根据查找表提供的地址信息将数据写入到cache中,新写入cache中的数据与主存中的原始数据不一致,所以叫做脏数据。
-
写回策略
此时写入操作结束,速度快,但不一致
-
写穿策略
将脏数据写入慢速的主存中才返回,响应速度慢,但保持一致
-
-
数据未命中
-
写分配法
需要将对应的数据块载入cache中,再进行和写命中一样的写入流程
-
直接将数据写入慢速的主存,返回
-
-
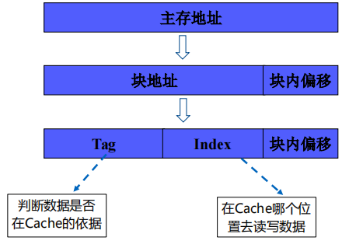
Cache地址映射机制
Cache的结构
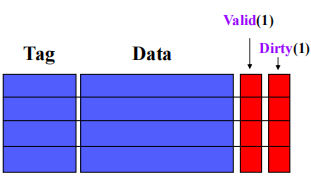
- Cache被分成若干行,每行的大小与主存块相同。
- Cache每行包含四部分,是Cache要保存的信息。
- Tag从CPU访问主存的地址中剥离得到
- Data是与主存交换的数据块
- Valid表示Cache中的数据是否有效
- Dirty表示主存中的数据是最新
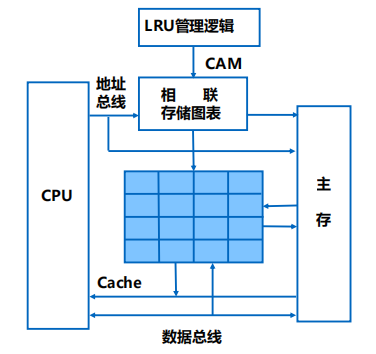
相联存储器
相联存储器的作用
- 判断CPU要访问的内容是否在Cache 中
判断的基本思路
-
根据不同规则抽取主存地址的部分内容作为查找的判据
-
如何实现快速查找
使用相联存储器,通过硬件并发查找
相联存储器的基本结构及工作原理
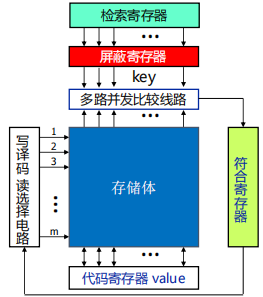
- 从地址中剥离出Key
- 以Key 为关键字全局硬件并发比较
- 存储体存放有效位、标记、数据等信息
- 符合寄存器存放Cache命中行信息
- 根据符合寄存器的信息取出命中行的数据
相联存储器的一种技术实现
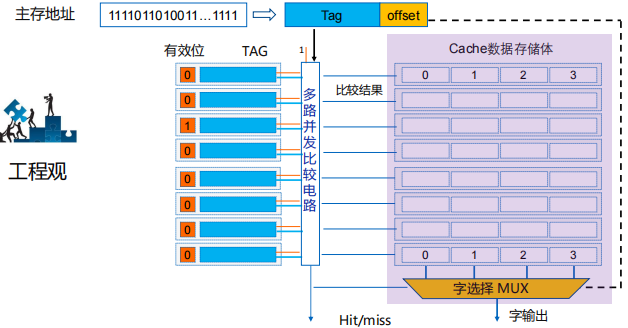
Cache地址映射与变换方法
主存与cache地址映射概述
-
主存数据如何迁至Cache才能实现快速查找?
-
常见的三种映射方式
-
全相联 (fully-associated)
-
直接相联 (direct mapped)
-
组相联 (set-associated)
-
###全相联映射的工作原理
-
主存分块,Cache行 (Line),两者大小相同;
-
主存分块后地址就从一维变成二维;
-
映射算法:主存的数据块可映射到Cache任意行,同时将该数据块地址对应行的标记存储体中保存。
-
设每块4个字,主存大小为1024个字,则第61个字的主存地址为:00001111 | 01 (块号 块内地址)
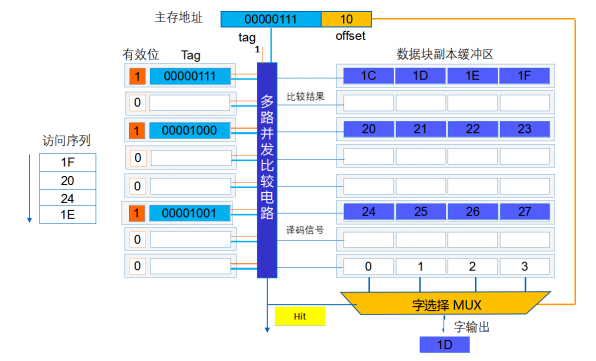
-
全相联映射的特点
-
Cache利用率高
-
块冲突率低
-
淘汰算法复杂
-
-
应用场合
- 小容量Cache
直接映射的工作原理
-
主存分块,Cache行 (Line),两者大小相同;
-
主存分块后还将以Cache行数为标准进行分区,
-
设每块4个字,主存大小为1024个字,Cache分为4行,第61个字的主存地址为:000011 | 11 | 01 (区号,区内块号,块内地址),主存地址从一维变成三维;
-
映射算法:Cache共n行,主存第j块号映射到Cache 的行号为:i=j mod n ,即主存的数据块映射到Cache特定行。

-
直接映射的特点
-
Cache利用率低
-
块冲突率高
-
淘汰算法简单
-
-
应用场合
- 大容量Cache
###组相联映射的工作原理
-
主存分块,Cache行 (Line),两者大小相同;
-
Cache分组(每组中包k行),本例假定K=4
-
主存分块后还将以Cache组数为标准进行分组;
-
设每块4个字,主存大小为1024个字,Cache分为4行,第61个字的主存地址为:0000111 1 01 (组号,组内块号,块内地址)主存地址从一维变成三维;
-
映射算法:Cache共n组,主存第j块号映射到Cache 的组号为:i=j mod n,即主存的数据块映射到Cache特定组的任意行。
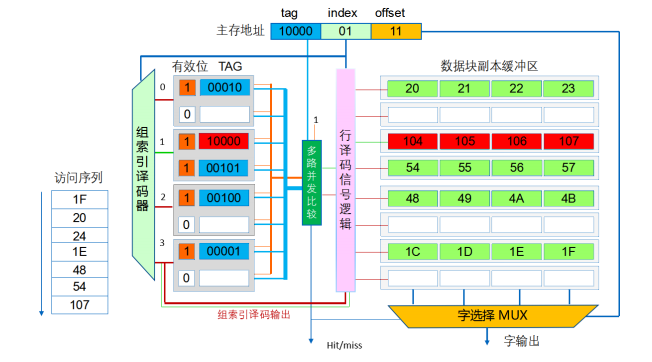
替换算法
- 程序运行一段时间后,Cache存储空间被占满,当再有新数据要调入时,就需要通过某种机制决定替换的对象。
先进先出法-FIFO
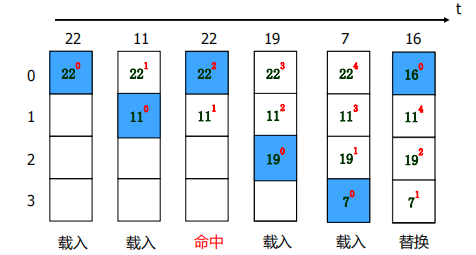
最不经常使用法—LFU
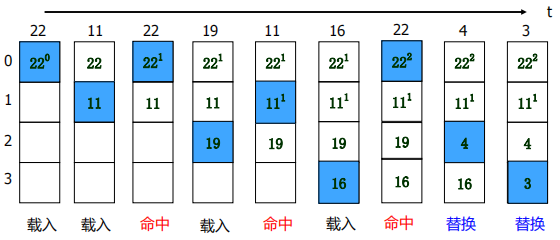
近期最少使用法— LRU
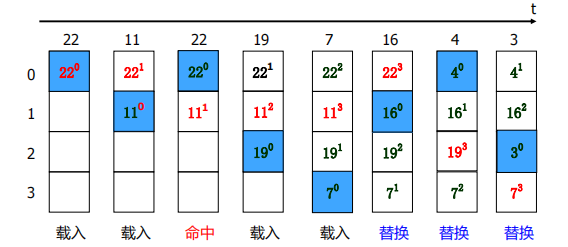
随机替换算法
- 就是随机的选取一行进行替换
- 用于TLB表中的替换
TLB (Translation Lookaside Buffer)转换检测缓冲区是一个内存管理单元,用于改进虚拟地址到物理地址转换速度的缓存。 TLB是一个小的,虚拟寻址的缓存,其中每一行都保存着一个由单个PTE (Page Table Entry, 页表 项)组成的块。
高速缓冲存储器例题选讲
例1 假定主存和Cache之间采用直接映射方式,块大小为16B。Cache数据区容量为64KB,主存地址为32位,按字节编址,数据字长32位。要求: 给出直接映射方式下主存地址划分,完成Cache访问的硬件实现,计算Cache容量
问题1:
- 分析:1个B表示1个字节(Byte),也就是8位(bit),题目中按字节编址是重点。
- 块内偏移4位(offest):
由题得,16B可以用4位(bit)表示其地址,因为是按字节编址故只考虑有多少个B - 行索引12位(index):
已知Cache数据区容量为64KB,则:
64KB = (64x1024B)/16B = 4KB = 4096B ,则需要12位(bit) - 区地址(tag):
至此确定了,CPU寻址数据的低16位(bit),即块内偏移4位(offest)+行索引12位(index)
用数据字长32 - (4+12) = 16(bit)表示区地址
问题2:

问题3:
-
分析:cache的容量分两部分,行数 x 行的容量
行容量: 有效位 + 区地址(和主存地址的区地址位对应) + 块内容量 (通过块内偏移w位算出)
行数:即行索引的位能表示的行数
直接相联cache的实际容量 $ = n \times (1+s-r+8\times 2^w)$
cache容量 =
-
这里的1 Kbit = 125 B , 8bit = 1B,可以不化简
例2 设某机内存容量为16MB,Cache的容量16KB,每块8个字,每个字32位.设计一个四路组相联映射(即Cache内每组包含4个字块)的Cache组织方式。1)求满足组相联映射的主存地址字段中各字段的位数。2)设Cache的初态为空,CPU从主存第0号单元开始连续访问100个字(主存一次读出一个字),重复此次序读8次,求存储访问的命中率。3)若Cache的速度是主存速度的6倍,求存储系统访问加速比
问题1:
-
分析:已知内存容量为16MB、Cache的容量16KB、每块8个字、每个字32位,cache的容量 = 行数 x 行的容量。
块内偏移(offset):
虚拟存储器
TLB
RAID
- 微信
