""" Please note, this code is only for python 3+. If you are using python 2+, please modify the code accordingly. """ from __future__ import print_function import tensorflow as tf import numpy as np import tensorflow.compat.v1 as tf
### create tensorflow structure end ### # 会话 sess = tf.compat.v1.Session() # tf.initialize_all_variables() no long valid from # 2017-03-02 if using tensorflow >= 0.12 # 虽然上面建立了变量,但是在神经网络种还没有初始化我们的变量 ifint((tf.__version__).split('.')[1]) < 12andint((tf.__version__).split('.')[0]) < 1: init = tf.compat.v1.initialize_all_variables() else: init = tf.compat.v1.global_variables_initializer() # 指针指向我处理的地方,处理的地方被激活 sess.run(init) # 使得神经网络一步步训练 for step inrange(201): sess.run(train) if step % 20 == 0: print(step, sess.run(Weights), sess.run(biases))
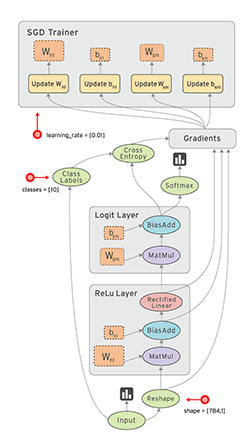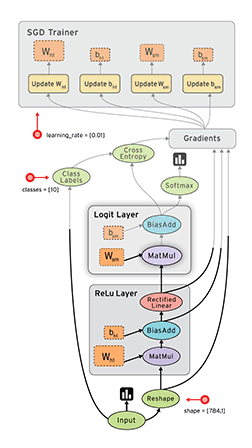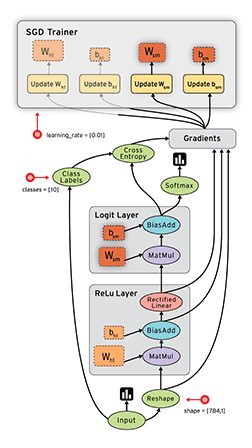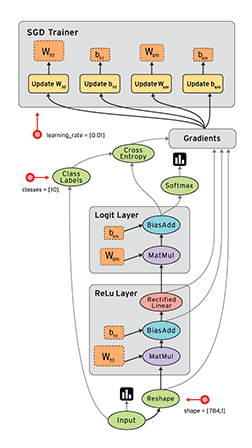
Session会话的控制
用于控制运算过程,等到数据准备好再运算
""" Please note, this code is only for python 3+. If you are using python 2+, please modify the code accordingly. """ from __future__ import print_function import tensorflow as tf tf.compat.v1.disable_eager_execution() matrix1 = tf.constant([[3, 3]]) matrix2 = tf.constant([[2], [2]]) product = tf.matmul(matrix1, matrix2) # matrix multiply np.dot(m1, m2)

 微信
微信