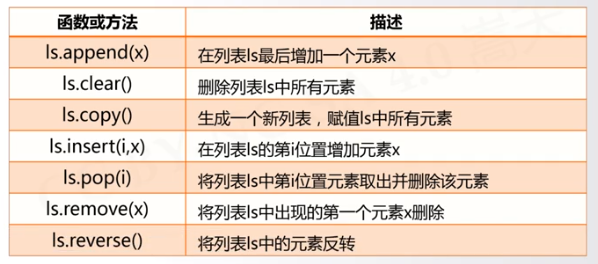
for <循环变量> in <遍历结构>: <语句块> for i inrange(N): # range(N)产生数字序列,包含N个元素 0 到 N-1. <语句块> for i inrange(M,N,K): #产生以M开始不到N的以K为步长取数的序列 for c in s : #字符串遍历,s是字符串,取出s中每个字符到循环变量中,执行语句 for item in ls : #对列表进行遍历,取出每个列表元素遍历 [123,"PY",456] for line in fi : #文件遍历循环,fi文件标识符,遍历文件每一行, print(line) #打印每行
还可以对元组等遍历循环,只要是多个元素组成的数据结构,都可以用for in 遍历
逐一从遍历结构中提取元素到循环变量中,然后执行语句块
while循环
while <条件判断> : <语句块>
循环控制保留字
break 和 continue 与 C 含义相同
for c in"PYTHON" : if c =="T": break#或者写continue print(c , end ='')
循环高级用法
#else没有被break退出时,循环正常完成,则执行else语句 #for循环加else for <循环变量> in <遍历结构> : <语句块1> else: <语句块2> #while循环加else while <条件> : <语句块1> else: <语句块2>
0x5 random库使用
random库介绍
random库时使用随机数的python标准库,主要用于生成随机数
伪随机数:采用梅森旋转算法生成的伪随机序列中元素
import random 基本随机数函数:seed(),random() 扩展随机数函数:randint(),getrandbits(),uniform(),randrange(),choice(),shuffle()
#CalPiv1.py pi = 0 N = 100 for k inrange(N): pi += 1/pow(16,k)*( \ # \ 可用于换行,不影响程序运行可以多次使用,提高可读性 4/(8*k +1) - 2/(8*k +4) - \ 1/(8*k +5) - 1/(8*k+6)) print("圆周率值是:{}".format(pi))
输出: 圆周率值是:3.141592653589793
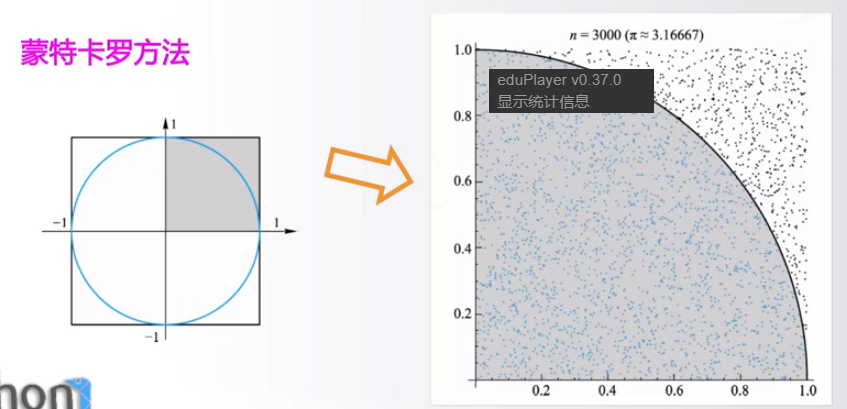
蒙特卡罗法
#CalPiv1.py from random import random from time import perf_counter DARTS = 10000*10000 hits = 0.0 start = perf_counter() for i inrange(1,DARTS+1): x,y = random(),random() dist = pow(x**2+y**2,0.5) if dist <= 1.0: hits = hits + 1 pi = 4 *(hits/DARTS) print("圆周率值是:{}".format(pi)) print("运行时间是:{:.5f}s".format(perf_counter()-start))
圆周率值是:3.143908 运行时间是:0.71663s
圆周率值是:3.14156908 运行时间是:59.99088s
理解方法思维
数学思维
计算思维
四色定理
程序运行时间分析
程序运行80%的时间消耗在不到10%的循环代码上
用于求解某个特定图形的面积
函数和代码复用
0x1 函数的定义及使用
函数的理解与定义
是一种抽象
定义的时候可以没有参数,但必须有括号
def <函数名>(参数): <函数体> return <返回值> 示例: defdayUP(df):#函数dayUP dayup = 1 for i inrange(365): if i % 7in[6,0]: dayup = dayup*(1 - 0.01) else: dayup = dayup * (1 + df) return dayup
示例: #1 deffact(n,m=1): s = 1 for i inrange(1,n+1): s *= i return s//m print(fact(10)) 3628800
#2计算n的阶乘,m = 1是默认的参数,不给指定参数则默认为1 deffact(n,m=1): s = 1 for i inrange(1,n+1): s *= i return s//m print(fact(10,5)) 725760
可变参数传递
#多个可变参数调用 deffact(n,*b):# *b表示可变参数 s = 1 for i inrange(1,n+1): s *= i for item in b : #如果b是一个列表, in b 将依次调用 b 中的值赋给item s *= item return s
示例:n!乘数 deffact(n,*b):# *b表示可变参数 s = 1 for i inrange(1,n+1): s *= i for item in b : #如果b是一个列表, in b 将依次调用 b 中的值赋给item s *= item return s print(fact(10,11,12,13)) print(fact(13))
6227020800 6227020800
函数调用时,参数可以按照位置或名称方式传递(代表地址)
位置传递
名称传递
函数的返回值
return,和c类似,不一定有返回值,或者传多个
但是返回的语法不同
多个返回的是 元组数据类型
>>> deffact(n,m=1) : s = 1 for i inrange(1,n+1): s *= i return s//m,n,m
>>> f = lambda : "lambda函数" >>> print(f()) lambda函数
建议使用def定义函数,特殊情况使用lambda
0x2 实例七段数码管绘制
问题分析
七段不同的数码管的亮暗,可以显示数字,字母
用程序绘制七段数码管
效果
基本思路
绘制单个数字,对应数码管
获得一串数字,一一表示
获得系统时间,表示出来
代码
第一步,绘制单个数字,对应数码管
import turtle defdrawLine(draw):#单段数码管,函数绘制一条线,并且判断该线是越过还是画 turtle.pendown()if draw else turtle.penup() turtle.fd(40) turtle.right(90) defdrawDight(digit):#根据数字绘制七段数码管 drawLine(True) if digit in [2,3,4,5,6,8,9] else drawLine(False) drawLine(True) if digit in [0,1,3,4,5,6,7,8,9] else drawLine(False) drawLine(True) if digit in [0,2,3,5,6,8,9] else drawLine(False) drawLine(True) if digit in [0,2,6,8] else drawLine(False) turtle.left(90) drawLine(True) if digit in [0,4,5,6,8,9] else drawLine(False) drawLine(True) if digit in [0,2,3,5,6,7,8,9] else drawLine(False) drawLine(True) if digit in [0,1,2,3,4,7,8,9] else drawLine(False) turtle.left(180) turtle.penup() #为绘制后续数字确定位置 turtle.fd(20) #为绘制后续数字确定位置
第二步,获得一串数字,一一表示
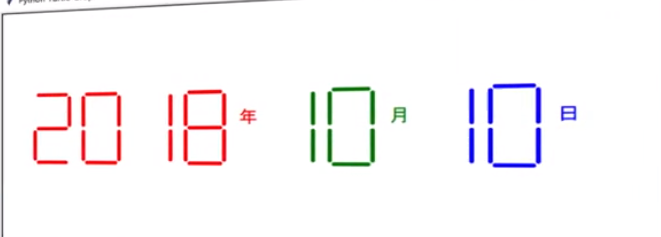
defdrawDate(date):#获得要输出的数字 for i in date: drawDight(eval(i)) #通过eval()函数将数字变成整数 defmain(): turtle.setup(800,350,200,200) turtle.penup() turtle.fd(-300) turtle.pensize(5) drawDate('20181010') turtle.hideturtle() turtle.done() main()
第三步,获得系统时间,表示出来
import turtle import time defdrawLine(draw):#单段数码管,函数绘制一条线,并且判断该线是越过还是画 turtle.pendown()if draw else turtle.penup() turtle.fd(40) turtle.right(90) defdrawDight(digit):#根据数字绘制七段数码管 drawLine(True) if digit in [2,3,4,5,6,8,9] else drawLine(False) drawLine(True) if digit in [0,1,3,4,5,6,7,8,9] else drawLine(False) drawLine(True) if digit in [0,2,3,5,6,8,9] else drawLine(False) drawLine(True) if digit in [0,2,6,8] else drawLine(False) turtle.left(90) drawLine(True) if digit in [0,4,5,6,8,9] else drawLine(False) drawLine(True) if digit in [0,2,3,5,6,7,8,9] else drawLine(False) drawLine(True) if digit in [0,1,2,3,4,7,8,9] else drawLine(False) turtle.left(180) turtle.penup() #为绘制后续数字确定位置 turtle.fd(20) #为绘制后续数字确定位置 defdrawDate(date):#获得要输出的数字 for i in date: drawDight(eval(i)) #通过eval()函数将数字变成整数 defmain(): turtle.setup(800,350,200,200) turtle.penup() turtle.fd(-300) turtle.pensize(5) drawDate(time.strftime("%H%M%S")) turtle.hideturtle() turtle.done() main()
代码优化
增加绘制间的距离
增加绘制年月日
获取时间
import turtle import time defdrawGap(): turtle.penup() turtle.fd(5) defdrawLine(draw):#单段数码管,函数绘制一条线,并且判断该线是越过还是画 drawGap() turtle.pendown()if draw else turtle.penup() turtle.fd(40) drawGap() turtle.right(90) defdrawDight(digit):#根据数字绘制七段数码管 drawLine(True) if digit in [2,3,4,5,6,8,9] else drawLine(False) drawLine(True) if digit in [0,1,3,4,5,6,7,8,9] else drawLine(False) drawLine(True) if digit in [0,2,3,5,6,8,9] else drawLine(False) drawLine(True) if digit in [0,2,6,8] else drawLine(False) turtle.left(90) drawLine(True) if digit in [0,4,5,6,8,9] else drawLine(False) drawLine(True) if digit in [0,2,3,5,6,7,8,9] else drawLine(False) drawLine(True) if digit in [0,1,2,3,4,7,8,9] else drawLine(False) turtle.left(180) turtle.penup() #为绘制后续数字确定位置 turtle.fd(20) #为绘制后续数字确定位置 defdrawDate(date):#改获得日期格式为,'%Y-%m=%d+',判断符号进行替换 turtle.pencolor("red") for i in date: if i == '-': turtle.write('年',font=("Arial",30,"normal")) turtle.pencolor("green") turtle.fd(40) elif i == '=' : turtle.write('月',font=("Arial",30,"normal")) turtle.pencolor("blue") turtle.fd(40) elif i == '+' : turtle.write('日',font=("Arial",30,"normal")) else: drawDight(eval(i)) #通过eval()函数将数字变成整数 defmain(): turtle.setup(800,350,200,200) turtle.penup() turtle.fd(-300) turtle.pensize(5) drawDate(time.strftime('%Y-%m=%d+',time.gmtime())) turtle.hideturtle() turtle.done() main()
举一反三
理解模块化方法思维:确定模块接口,封装功能
规则化思维:抽象过程为规则,
化繁为简:分治
扩展
到小数点
倒计时时刷新
14段的数码管
数码管有更多段
0x3 代码复用与函数递归
代码复用与模块化设计
代码资源化:程序代码是一种用来表达计算的”资源“
代码抽象化:使用函数等方法对代码赋予更高级别的定义
代码复用:函数和对象
函数:将代码命名,在代码层面建立了初步抽象
对象:属性和方法,在函数之上再次组织进行抽象
<a>.<b> 和 <a>.<b>()
分而治之
通过函数或对象分装将程序划分为模块及模块间的表达
具体包括:主程序、子程序、和子程序的关系
紧耦合 交流多无法独立
松耦合 交流少可以独立
函数内部要紧耦合,模块之间要松耦合
函数递归的理解
函数中调用自身
函数递归的调用过程
deffact(n): if n == 0: return1 else : return n*fact(n-1) fact(5)
函数递归实例解析
字符串反转
将字符串s反转后输出
s[::-1]
函数 +分支结构
递归链条
递归基例
>>> defrvs(s): if s == "" : return s else : return rvs(s[1:])+s[0]
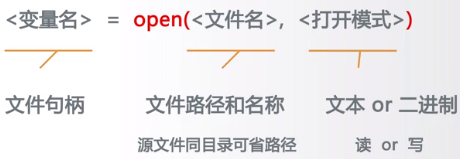
import jieba txt = open("threekingdoms.txt","r",encoding="utf-8").read() excludes = {"将军","却说","荆州","二人","不可","不能","如此","如何","商议","军士","左右","军马","引兵","次日","大喜","天下","东吴","于是","今日","不敢","魏兵"} words = jieba.lcut(txt) counts = {} for word in words: iflen(word) == 1: continue elif word == "诸葛亮"or word == "孔明曰": rword = "孔明" elif word == "关公"or word == "云长": rword = "关羽" elif word == "玄德"or word == "玄德曰": rword = "刘备" elif word == "孟德"or word == "丞相": rword = "曹操" else: rword = word counts[rword] = counts.get(rword,0) + 1 for word in excludes: del counts[word] items = list(counts.items()) items.sort(key=lambda x:x[1],reverse=True) for i inrange(8): word,count = items[i] print("{0:<10}{1:>5}".format(word,count))
fname = input("请输入要打开的文件名称:") fo = open(fname,"r") for line in fo.readlines(): print(line) fo.close()
分行读入、逐行处理
fname = input("请输入要打开的文件名称:") fo = open(fname,"r") for line in fo: print(line) fo.close()
数据的文件写入
writelines直接将文字拼接写入文件,没有空格换行
输入位置指针,描述了当前在文件内写入的具体内存位置
fo = open("output.txt","w+") ls = ["中国","法国","美国"] fo.writelines(ls) for line in fo: print(line) fo.close()
#此时输入指针在输入的末尾,之后是没有内容的,固没有输出 #修改如下,使用seek方法
fo = open("output.txt","w+") ls = ["中国","法国","美国"] fo.writelines(ls) fo.seek(0) #将输入指针返回到最开始 for line in fo: print(line) fo.close()
0x2 实例:自动轨迹绘制
自动轨迹绘制
根据脚本来绘制图形
写数据绘制图形
是自动化程序的重要内容
基本思路
定义数据文件格式(接口)
根据文件接口解析参数绘制图形
编制数据文件
数据接口定义
根据个人需求
编写对应程序
map函数,将第一个参数对应的函数作用于一个列表或集合的每个元素
import turtle as t t.title('自动轨迹绘制') t.setup(800,600,0,0) t.pencolor("red") t.pensize(5) #数据读取 datals = [] f = open("data.txt") for line in f: line = line.replace("\n","") datals.append(list(map(eval,line.split(",")))) f.close() #自动绘制 for i inrange(len(datals)): t.pencolor(datals[i][3],datals[i][4],datals[i][5]) #找到第i个参数,获取第3个值、第4个值,第5个值,即RGB参数 t.fd(datals[i][0]) #读取0位数据,获得绘制长度 if datals[i][1]: #根据判断是否转向,选择左右转的角度 t.right(datals[i][2]) else: t.left(datals[i][2])
理解方法思维
自动化思维
接口化设计
二维数据应用
拓展
增加更多接口
增加功能
增加应用动画绘制
0x3 一维数据的格式化和处理
数据组织的维度
线性方式组织
二维方式组织
多维、高维
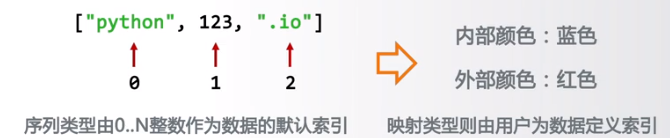
一维数据
由对等关系的有序或无序数据构成,采用线性方式组织
对应列表数组和集合等概念
二维数据
由多个一维数据构成,是一维数据的组合形式
仅利用最基本的二元关系展示数据间的复杂结构
例如 键值对定义
数据的操作周期
存储、表示、操作
存储格式、数据类型、操作方式
一维数据的表示
如何用程序类型表达一维数据
如果数据间有序:使用列表类型
可以用for循环遍历
数据无序:使用集合类型
可以使用for循环遍历
一维数据的存储
存储方式
空格分隔 即存储的数据之间需要空格
但数据中不能由空格
逗号分隔 也如空格存在缺点
一般用特殊符号分隔
一维数据的处理
读入
从空格分隔的文件中读入数据
txt = open(fname).read() ls = txt.split() f.close()
从特殊分隔的文件中读入数据
txt = open(fname).read() ls = txt.split("$") f.close()
写入
采用空格方式写入数据文件
ls = ['中国','美国','日本'] f = open(fname,'w') f.write(''.join(ls)) #将' '作为分隔放到ls数据之间 f.close()
特殊分隔的方式写入数据文件
ls = ['中国','美国','日本'] f = open(fname,'w') f.write('$'.join(ls)) #将'$'作为分隔放到ls数据之间 f.close()
0x4 二维数据的格式化和处理
二维数据的表示
使用表格形式,使用二维列表
类似于C语言中的二维数组
使用列表类型
遍历需要两层for循环
数据维度是数据的组织形式
一维数据:列表和集合类型
有序用列表,无序用集合
CSV数据存储格式
CSV Comma-Separated Values
用逗号来分隔值的一种存储方式
是国际通用的一二维数据存储格式,一般.CSV扩展名
每行一个一维数据,采用逗号分隔,无空行
Excel和一般编辑软件都可以读入或另存为CSV文件
二维数据的存储
如果某个元素缺失,逗号仍要保留
二维数据的表头可以作为数据存储,也可以另行存储
逗号为英文半角逗号,逗号与数据至今无额外空格
数据中的逗号可以用引号标识,也可加转义符
数据如何存的,按行存或者按列存都可以,具体由程序决定
一般索引习惯:
ls [row][column]
二维数据的处理
二维数据的读入处理
从CSV格式的文件读入数据
fo = open(fname) ls = [] for line in fo: line = line.replace("\n","") ls.append(line.split(",")) fo.close()
将数据写入CSV格式的文件
ls = [[],[],[]] #二维列表 f = open(fname,'w') for item in ls: f.write(','.join(item) + '\n') f.close()
遍历
采用二层循环
ls = [[1,2],[3,4],[5,6]] #二维列表 for row in ls: for column in row: print(column)





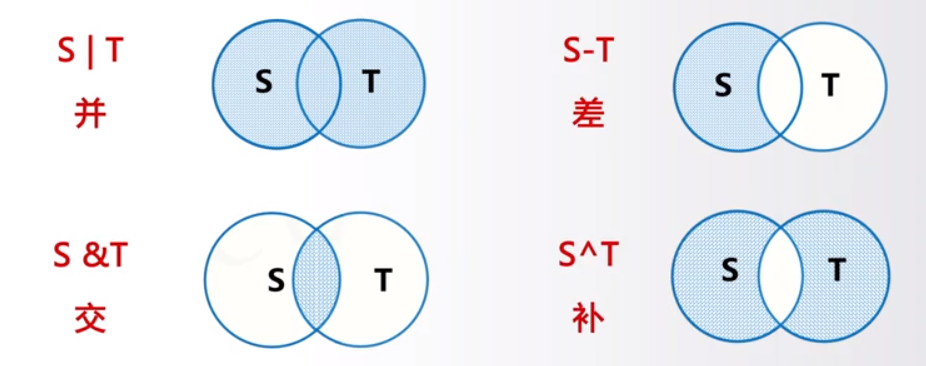
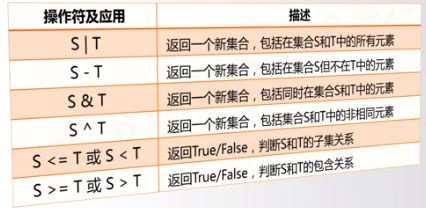



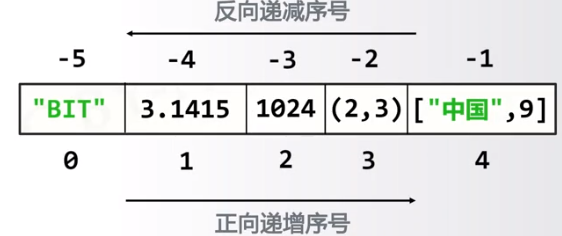
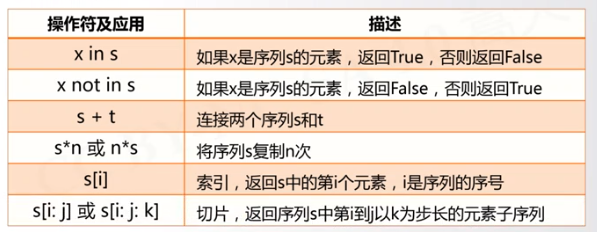
















 微信
微信