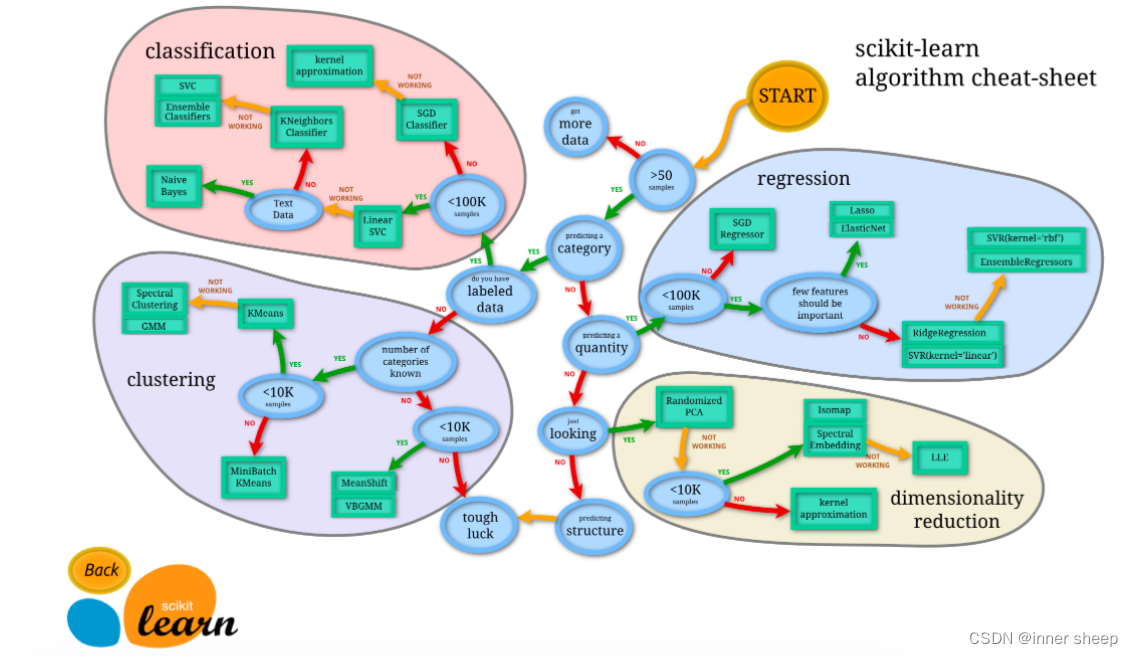
import numpy as np from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier
import numpy as np from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression import matplotlib.pyplot as plt
import numpy as np from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression import matplotlib.pyplot as plt
import numpy as np from sklearn import preprocessing from sklearn.datasets._samples_generator import make_classification from sklearn.model_selection import train_test_split from sklearn.svm import SVC import matplotlib.pyplot as plt
# 通过一个个测试,来查看我的参数选取范围即好坏 k_range = range(1, 31) k_scores = [] for k in k_range: knn = KNeighborsClassifier(n_neighbors=k) scores = cross_val_score(knn, X, y, cv=10, scoring='accuracy') # for classification # 如果是线性回归问题,则可以用误差打分,加 - 是因为生成的值是负值,误差要选小的 # loss = -cross_val_score(knn,X,y,cv=10,scoring='mean_squared_error') # for regression scores.append(scores.mean())
plt.plot(k_range, k_scores) plt.xlabel('Value of K for KNN') plt.ylabel('Cross-Validated Accuracy') plt.show()
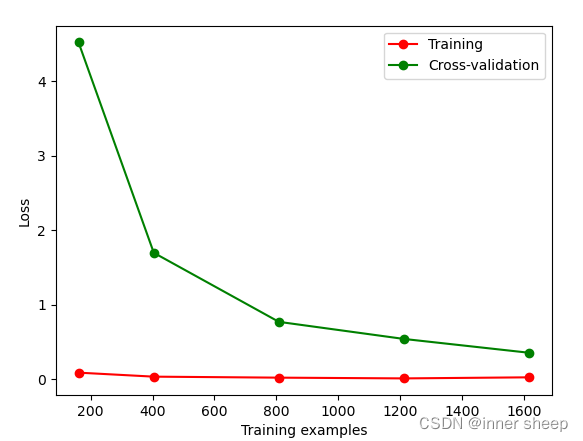
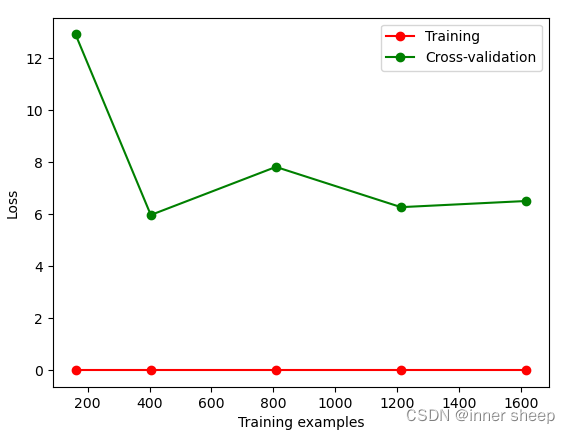
交叉验证2-过拟合
多项式过多,过度拟合了当前的数据集
""" Please note, this code is only for python 3+. If you are using python 2+, please modify the code accordingly. """ from __future__ import print_function from sklearn.model_selection import learning_curve from sklearn.datasets import load_digits from sklearn.svm import SVC import matplotlib.pyplot as plt import numpy as np
from __future__ import print_function from sklearn.model_selection import validation_curve from sklearn.datasets import load_digits from sklearn.svm import SVC import matplotlib.pyplot as plt import numpy as np
# 获取数据 digits = load_digits() X = digits.data y = digits.target